
Detekcija anomalija – Deo II
U prvom delu smo govorili o tome šta su anomalije i koje tehnike se koriste za njihovu detekciju. Ako želite da vidite da li trenutne cene akcija poznate prodavnice video igara GameStop predstavljaju anomalije, ostanite sa nama i uz ovaj blog naučite više o njihovoj primeni. Prvo ćemo govoriti o detekciji anomalija u vremenskim serijama, zatim o detekciji anomalija pomoću grafova i na kraju videti kako su se ponašale cene akcija prodavnice GameStop u poslednjih devetnaest godina.
Sadržaj
Detekcija anomalija u vremenskim serijama
Neke bitne primene detekcije anomalija u vremenskim serijama podataka su zdravstvo, poremećaji eko sistema, otkrivanje upada i upravljanje sistemima za vazduhoplovstvo. U ovom delu identifikovaćemo različite tipove anomalija u vremenskim serijama i fokusiraćemo se na polunadgledanu detekciju anomalija. Većina tehnika za detekciju anomalija se bavi tačkastim anomalijama i ne uzima u obzir redosled podataka. Na narednoj slici možemo videti elektrokardiogram pacijenta. Deo grafika obojen u crveno označava anomaliju zato što se ovako niska vrednost zadržava duži vremenski period. Ako bismo posmatrali ovu nisku vrednost samo za sebe, ona ne bi bila anomalija jer se pojavljuje na više mesta. Dakle, ako bismo ignorisali vremenski aspekt, propustili bismo ovu anomaliju. 
Detekcija kontekstualnih anomalija u vremenskim serijama
U ovom slučaju, anomalije su individualne instance vremenske serije podataka i one su anomalije samo u tom specifičnom kontekstu, u suprotnom nisu. Na slici ispod je prikazana mesečna temperatura nekog područja. Temperatura od oko 2 stepena Celzijusa (temperatura \(t_1\)) je normalna u Decembru, ali ovakva temperatura u Junu (temperatura \(t_2\)) je anomalija. 
Detekcija anomalijskih podintervala u datoj vremenskoj seriji
U ovom slučaju pokušavamo da pronađemo anomalijski podinterval u odnosu na dati duži interval (vremensku seriju). Anomalijski podintervali se nazivaju diskordima (discords). Na slici za elektrokardiogram to bi bio podinterval u kome je grafik obojen crvenom bojom. U slučaju kada je podinterval jedinične dužine, problem je ekvivalentan nalaženju kontekstualnih anomalija u vremenskim serijama podataka.
Detekcija anomalija uzimajući u obzir skup podataka
Ovaj slučaj pokušava da utvrdi da li je vremenska serija anomalijska u odnosu na skup podataka date vremenske serije za treniranje. Skup podataka može biti dat u dva oblika. Prvi tip se sastoji samo od normalnih vremenskih serija, što je polunadgledana okolnost. Drugi tip se sastoji od normalnih podataka i anomalija, pri čemu su i jedni i drugi podaci labelirani, i pretpostavlja se da je većina podataka normalnog tipa. Na narednoj slici su predstavljeni NASA-ini podaci o kvaru diska rotacionog motora, pri čemu leva slika je referentna slika (zdrav motor), a desna je testna slika (zdrav i ispucao disk).
Izazovi detekcija anomalija u vremenskim serijama
Neki od glavnih izazova predstavljaju:
\( 1. \) Postoji puno načina za definisanje anomalije u vremenskoj seriji – jedan događaj u okviru vremenske serije, podinterval u okviru vremenske serije ili čak cela vremenska serija može biti anomalija u odnosu na skup normalnih vremenskih serija;
\( 2. \) Za detektovanje anomalijskih podintervala često je potrebno znati tačnu dužinu podintervala;
\( 3. \) Trening i test vremenske serije mogu biti različitih dužina;
\( 4. \) Najbolje mere sličnosti/udaljenosti koje se mogu koristiti za različite tipove vremenskih serija nije lako utvrditi. Na primer, Euklidsko rastojanje ne proizvodi uvek dobre rezultate zato što je veoma osetljivo na netipične vrednosti i ne može se koristiti kada su vremenske serije različitih dužina;
\( 5. \) Algoritmi za detekciju anomalija su veoma podložni šumovima u vremenskim serijama podataka, zato što je često teško razlikovati anomalije i šumove u podacima;
\( 6. \) Vremenske serije u realnim primenama su uglavnom dugačke. Zbog toga, kako se ta dužina povećava, računska kompleksnost se takođe povećava;
\( 7. \) Većina algoritama za detekciju anomalija očekuje da će više vremenskih serija biti uporedivo po veličini, što u većini slučajeva nije tačno.
Tipovi vremenskih serija podataka
Razmatraćemo dve ključne karakteristike vremenskih serija: periodičnost i sinhronost. Kombinacija ove dve karakteristike će nam dati četiri različita tipa vremenskih serija. Neka je dat skup podataka od \(n\) normalnih vremenskih serija \(T= { t_1,t_2,…,t_n }\) koje možemo posmatrati na sledeći način:
Periodične i sinhrone – Ovo je najjednostavnija okolnost, gde svako \(t_i ϵ T \) ima konstantan vremenski period \(p\) i svaka vremenska serija je privremeno poravnata (počinje od iste vremenske instance). Na slici je prikazano nedeljna proizvodnja struje u elektrani.

Periodično – sinhrone vremenske serije Aperiodične i sinhrone – Vremenske serije nemaju nikakav period, ali su privremeno poravnate. Na slici su prikazane trenutne mere zabeležene na ventilu na svemirskom šatlu.

Aperiodično – sinhrone vremesnke serije Periodične i asinhrone – Svaka vremenska serija ima specifičan period, ali nisu privremeno poravnate. Na slici je prikazan rad indukcionog motora.

Periodično – asinhrone vremenske serije Aperiodične i asinhrone – Vremenske serije nemaju period i nisu privremeno poravnate. Na slici su prikazani fiziološki signali sa PhysioNet repozitorijuma.

Aperiodično – asinhrone vremenske serije
Pregled postojećih tehnika za detekciju anomalija u vremenskim serijama
Tehnike za detektovanje anomalija u vremenskim serijama se mogu klasifikovati u zavisnosti od procesa pronalaženja anomalija (proceduralna dimenzija) ili načina na koji se podaci tranformišu pre detektovanja anomalija (transformacijska dimenzija). Obe dimenzije su ortogonalne.
Tehnika zasnovana na prozoru (Window based) deli date vremenske serije na prozore (podintervale) fiksirane veličine kako bi lokalizovala uzrok anomalije u okviru jednog ili više prozora. Ova tehnika pravi lenj model koji poredi testne vremenske serije sa datim trening serijama kako bi procenile score anomalije.
Skriveni Markovi modeli (Hidden Markov Models) su mašine koje kategorizuju sistem koristeći uočljive parametre. Ova tehnika i tehnika zasnovana na regresiji grade parametarske modele na trening podacima koji na osnovu verovatnoće dodeljuju score anomalije testnim vremenskim serijama.
Kako bi se izbegli izazovi, transformacija podataka se vrši pre primene tehnika za detekciju anomalija. Agregacija se vrši kako bi se smanjila dimenzionalnost agregiranjem uzastopnih vrednosti. Obrada signala i diskretizacija smanjuju dimenzionalnost podataka na drugačiji način i transformišu ulazne podatke u drugi domen koji se može koristiti kako bi se dobilo na računskoj efikasnosti.
Detekcija anomalija pomoću grafova
Puno tipova podataka sadrži vremenske ili prostorne veze između svojih elemenata koje se veoma lepo prikazuju pomoću grafova. Na primer, ako pomoću grafova predstavimo transakcije na kreditnim karticama, možemo napraviti veze (grane) između transakcija koje se odvijaju u krugu od jednog kilometra ili u roku od par sekundi između sebe.
Graf se sastoji od temena (čvorova) i grana koje ih povezuju. Ivice mogu biti usmerene ili neusmerene. Svako teme i grane sadrže labelu pomoću koje se identifikuje tip i labele ne moraju biti jedinstvene.
Za detekciju anomalija pomoću grafova koristićemo Subdue sistem koji je u suštini algoritam za detektovanje šablona (podstruktura) koji se ponavljaju u grafovima. Podstruktura je povezani podgraf celokupnog grafa. Subdue zadržava uređenu listu otkrivenih podstruktura koja se naziva lista roditelj. U početku lista roditelj se sastoji samo od podstruktura sa jednim temenom za svaku jedinstvenu labelu temena. Subdue konstantno uklanja sve podstrukture iz lista roditelja, generiše i procenjuje proširenja i ubacuje dodatke na listu. Dodaci podstrukture se generišu tako što se dodaju nova temena (i odgovarajuće ivice) ili samo jedna grana unutar podstrukture. Kako se generišu nove strukture, održava se druga lista koja sadrži najbolje podstrukture otkrivene do tada. Kada se ovaj proces završi, prijavljuje se podstruktura sa najboljom vrednosti i koristi se kako bi se kompresovao graf pre nego što sledeća iteracija započne. Kompresovanje grafa se odnosi na zamenu svake instance podstrukture novim temenom koje predstavlja tu podstrukturu. Svaka podstruktura se procenjuje pomoću heuristike minimuma deskriptivne dužine (Minimum Description Length heuristic). Minimum deskriptivne dužine (ili samo deskriptivna dužina) je najmanji broj delova koji su potrebni da bi se kodirao deo podataka (Subdue sadrži algoritam koji aproksimira ovu vrednost za bilo koji graf). Koristeći ovu heuristiku, smatramo da je najbolja podstruktura ona koja minimizuje sledeću vrednost: \( F_1 (S,G) = DL(G│S)+DL(S) \), pri čemu je \(G\) ceo graf, \(S\) je podstruktura, \(DL(G│S)\) je deskriptivna dužina grafa \(G\) nakon kompresovanja korišćenjem podstrukture \(S\) i \(DL(S)\) je deskriptivna dužina podstrukture \(S\).



Detekcija anomalijskih podstruktura
Cilj detekcije anomalijskih podstruktura je da ispita ceo graf i da prijavi neobične podstrukture unutar njega. Treba napomenuti da nije dovoljno samo tražiti podstrukture koje se retko pojavljuju, zato što se očekuje da se veoma velike podstrukture retko pojavljuju.
Kao što je pomenuto, Subdue je mehanizam koji otkriva šablone u grafovima. Šabloni u ovom slučaju predstavljaju podstrukture koje proizvode male vrednosti za \(F_1(S,G)\). Cilj ovog pristupa je posmatrati anomalije kao suprotnost šablonima. Kako se šabloni pojavljuju često u grafu, anomalije se pojavljuju retko. Zbog toga je jedna od mogućih metoda tražiti velike vrednosti za \(F_1(S,G)\). Međutim, jedan od problema na koji se nailazi ovom metodom je u slučaju kada je \(S=G\). Tada će \(F_1(S,G)\) biti veoma veliko, štaviše biće veće od deskriptivne dužine grafa jer je \( F_1(S,G) = DL(G│S) + DL(S)= DL(G│G) + DL(G) \geq DL(G) \). Dakle, podstruktura koja bi sadržala ceo graf bi uvek bila označena kao anomalija. Sličan problem nastaje ako bi se podstruktura sastojala samo od jednog temena.
Zbog toga ćemo definisati heuristiku \(F_2(S,G) = Size(S) \ast Instances(S,G)\), pri čemu je \(Size(S)\) broj temena od \(S\), a \(Instances(S,G)\) je broj ponavljanja podstrukture \(S\) u grafu \(G\). Podstrukture ćemo smatrati anomalijama ako proizvode male vrednosti za \(F_2(S,G)\). Posmatrajmo ponovo graf dat na Slici 11. Tada je \(F_2(S,G) = Size(S) \ast Instances(S,G) = 1 \ast 1 = 1\). Ovo je najmanja moguća vrednost. Nekoliko dvotemenih podstruktura ima \(F_2 = 2\). Među njima su podstrukture prikazane na slikama ispod. 

Ova metoda je dobra za detektovanje specifičnih podstruktura bilo gde u grafu. U nekim situacijama može biti korisno razdvojiti graf na različite odvojene podgrafove i odrediti koliko je anomalijski svaki podgraf u odnosu na ostale.
Pretpostavimo da nam je data tabela transakcija na kreditnoj kartici i želimo da potražimo sumnjive transakcije. Neka se tabela sastoji od sledećih atributa:
amount – iznos transakcije;
num_trans – broj transakcija na ovom nalogu u poslednja 24 časa od transakcije;
trans_category – kategorija poslovnice u kojoj je obavljena transakcija (online, department store i drugo);
credit_limit – ograničenje na kartici;
months_active – koliko meseci je kartica aktivna pre transakcije.
Na naredne dve slike možemo videti primer jednog unosa, i graf koji predstavlja taj unos. 

Sada koristimo Subdue za detekciju anomalijskih podgrafova. Subdue se može primeniti na istom grafu za više iteracija. Posle svake iteracije graf se kompresuje koriteći otkrivenu podstrukturu. Drugim rečima, svaka instanca podstrukture se menja jednim čvorom. Sledeća iteracija će se obaviti na novokompresovanom grafu. Najbolje podstrukture će biti otkrivene u prvih nekoliko iteracija. Pretpostavićemo da se Subdue zaustavlja kada graf ne sadrži podstrukture koje imaju više od jedne instance.
Međutim, nije dovoljno samo sačekati da Subdue završi i onda proveriti koliko je podgrafova kompresovano. Sledeći primer će pokazati zašto bi ovo moglo izazvati probleme. Neka graf sadrži dva podgrafa koja su identična, ali su veoma neobična u odnosu na ceo graf. U većini iteracija ovi podgrafovi će ostati nekompresovani, zato što ne sadrže ni jedan uobičajeni šablon koji Subdue otkriva. U nekom trenutku, pošto ne postoji ništa jedinstveno ni za jedan od ova dva podgrafa, oni će biti kompletno kompresovani. Zbog toga ni jedan od ova dva podgrafa neće biti posmatran kao anomalija iako su oba podgrafa anomalije u odnosu na ceo garf.
Iz ovog primera vidimo da nam je potreban još jedan faktor – koliko brzo se vrši kompresija podgrafa. Na primer, pretpostavimo da posle svih iteracija podgrafovi \(A\) i \(B\) su kompresovani na polovinu svoje početne veličine. Ako je \(A\) kompresovan u prvoj iteraciji, a \(B\) u pedesetoj, podgraf \(B\) će biti više anomalijski od podgrafa \(A\).
Dakle, potrebna je mera koja uzima u obzir koliko podgrafova se kompresuje i koliko brzo se oni kompresuju. Svakom podgrafu dodelićemo vrednost \(A\). Što je veće \(A\), to je podgraf više anomalijski. \(A\) je dato formulom \(A = 1- \frac{1}{n} \sum_{i=1}^{n}(n-i +1) \ast c_i\), gde je \(n\) broj iteracija, a \(c_i\) je procenat podgrafa koji je kompresovan u \(i\)-toj iteraciji. \(c_i\) se preciznije definiše na sledeći način \(c_i = \frac{DL_{i-1}(G)-DL_i(G)}{DL_0(G)}\), gde je \(DL_j(G)\) deskriptivna dužina podgrafa nakon \(j\) iteracija.
Ideja je da svi podgrafovi za početnu vrednost uzimaju \(A\) – vrednost u iznosu 1 (odnosno, nisu anomalijski) i vrednosti se smanjuju kako se delovi podgrafa kompresuju kroz iteracije. Vrednost \( c_i \) varira između 0 i 1 (vrednost \(0\) znači da se podgraf nije promenio u \( i \) – toj iteraciji, dok vrednost 1 znači da je ceo podgraf kompresovan). Vrednost \( n-i+1 \) varira od \( n \) do \( 1 \) kako se \( i \) povećava, što povlači da vrednost \( A \) brže opada za kompresije koje se javljaju u početku. Vrednost \( \frac{1}{n} \) garantuje da će konačna vrednost biti između \(0\) i \(1\), kako je maksimalna vrednost sume n (ovo bi se desilo kada bi ceo podgraf bio kompresovan u prvoj iteraciji).
Primer
U primeru koji je prikazan u nastavku radićemo sa skupom podataka koji je dat na sledećem linku. U pitanju su podaci sa cenama akcija GameStop-a od 2002. do 2021. godine. Skup podataka se sastoji od sledećih kolona:
Date – datum kupoprodaje;
Open_price – početna cena akcije za taj dan;
High_price – najviša cena tog dana;
Low_price – najniža cena tog dana;
Close_price – zaključna cena akcije za taj dan;
Volume – ukupan broj kupljenih i prodatih akcija tog dana;
Adjclose_price – zaključna cena akcije za taj dan izmenjena tako da uključuje sve distribucije/korporativne akcije koje se dese pre otvaranja narednog dana.
Kako bismo detektovali anomalije u ovom skupu podataka koristićemo biblioteku anomalize koja je napisana u programskom jeziku R. Ova biblioteka je pogodna za otkrivanje anomalija u vremenskim serijama podataka i za stvaranje granica između normalnih podataka i anomalija. Prvo ćemo učitati sve biblioteke koje su nam potrebne.
library(anomalize)
library(tidyverse)
library(tibbletime)
library(tidyquant)
Zatim ćemo učitati skup podataka i prikazati podatke koje sadrži.
data <- as_tibble(read.csv("G:\\Marta\\Pmf\\GME_stock.csv", header=TRUE, stringsAsFactors=FALSE))
head(data)

Da bismo koristili biblioteku anomalize neophodno je da skup podataka bude objekat tipa tibble ili tbl_time, zbog čega smo koristili as_tibble(). Takođe je neophodno da datumi budu tip podataka date. U našem slučaju, kao što to možemo videti na prethodnoj slici, datumi su tipa character. Zato ćemo elemente iz kolone date pretvoriti u tip podataka date i sortiraćemo skup podataka po datumu.
data$date <- as.Date(data$date, format = c("%Y-%m-%d"))
data <- data[order(data$date), ]
head(data)
Sada skup podataka izgleda ovako:

Primenimo sada anomalize na sređen skup podataka.
anomalized_data %>%
time_decompose(close_price) %>%
anomalize(remainder) %>%
time_recompose()
head(anomalized_data)

Dakle, biblioteka uzima skup podataka i primenjuje tri različite funkcije na njega. Prvo, funkcija time_decompose() razlaže close_price kolonu na observed, season, trend i remainder kolone. Zatim, funkcija anomalize() vrši detekciju anomalija na koloni remainder i kao izlaz nam daje tri kolone remainder_l1, remainder_l2 i anomaly. Poslednja kolona anomaly je kolona koja nas interesuje. Ako se u njoj nalazi Yes to znači da je posmatrana instanca anomalija, a u slučaju No u pitanju je noramalan podatak. Na kraju, funkcija time_recompose() računa granice koje razdvajaju normalne podatke od anomalija.
Prikažimo još anomalije vizuelno.
plot_anomalized_data %>%
plot_anomalies(time_recomposed = TRUE, ncol = 3, alpha_dots = 0.25)
plot_anomalized_data

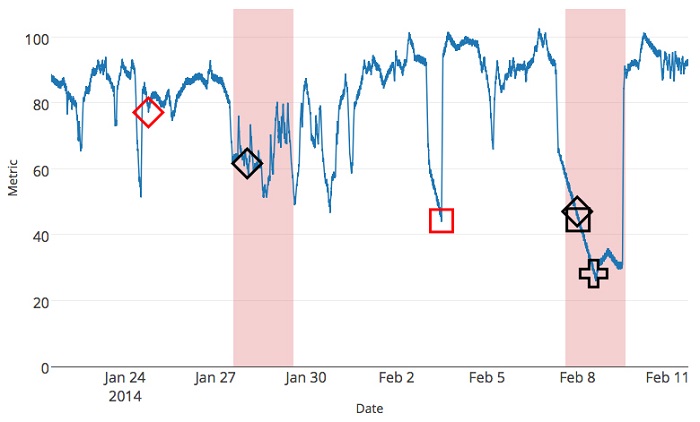
Svaka tačka na slici predstavlja instancu podataka. Crvene tačke predstavljaju anomalije, a crne predstavljaju normalne podatke. Možemo uočiti tri vremenske serije podataka sa anomalijama koje su prikazane na narednoj slici.

Ako ne bismo posmatrali vremenske serije, zaključili bismo da su se anomalije u ceni akcija javile samo 2021. godine. Na ovaj način uočili smo da su se javljale u jos 2 vremenska perioda.
Zaključak
Detekcija anomalija je veoma bitna kako bismo uočili neočekivane šablone u podacima i na taj način primetili ako nešto nije u redu. Videli smo kako to funkcioniše prilikom krađe identiteta, kao i sa trgovinom akcija. Takođe je bitno uočiti anomalje kako bismo sprečili da se tako nešto ponovi. Nadam se da Vam je ovaj rad probudio želju da o detekciji anomalija saznate još više.
Reference
Autor: Marta Dragicevic
Studentkinja master studija informatike na Prirodno-matematičkom fakultetu u Kragujevcu.
Osnovne akademske studije matematike završila je na Prirodno-matematičkom fakultetu u Kragujevcu, smer teorijska matematika.
Trenutno je zaposlena u firmi TechnoSigma.