Изометријски случај
Ради тестирања способности НМПФЗ да решавају ову врсту парцијалних диференцијалних једначина, најпре је од интереса изометријски случај, јер је он најједноставнији, будући да је брзина клизања филамената једнака нули. Код изометријског случаја, вишеслојни перцептрон као улаз узима позицију \(x\) доступног актинскиг сајта у односу на равнотежни положај миозинске главе и време \(t\), а предвиђа вероватноће закачињања миозинских глава за актинске сајтове \(n(x,t)\).
Имплементација
Комплетан код је дат на следећем листингу.
1import deepxde as dde
2import numpy as np
3import tensorflow as tf
4
5''' fixed parameters '''
6f1_0 = 43.3
7h = 15.6
8g1 = 10.0
9g2 = 209.0
10fzah = 4.0
11a = 1.
12
13# Verovatnoca kacenja
14def f(x,a):
15 return (1+tf.sign(x)) * (1-tf.sign(x-h)) * (f1_0*a*x/h) * 0.25
16
17# Verovatnoca raskacivanja
18def g(x):
19 return 0.5 * (1-tf.sign(x)) * g2 + \
20 0.25 * (1+tf.sign(x)) * (1-tf.sign(x-h)) * (g1*x/h) + \
21 0.5 * (1+tf.sign(x-h)) * (fzah*g1*x/h)
22
23# n = n(x,t)
24def pde(x, n):
25 dn_dt = dde.grad.jacobian(n, x, i=0, j=1)
26 loss = dn_dt - (1.0-n) * f(x[:,0:1],a) + n*g(x[:,0:1])
27 # Obezbedi pozitivna resenja
28 return loss + n*(1-tf.sign(n))
29
30# Computational geometry
31geom = dde.geometry.Interval(-20.8, 63)
32timedomain = dde.geometry.TimeDomain(0, 0.4)
33geomtime = dde.geometry.GeometryXTime(geom, timedomain)
34
35# Pocetni uslovi
36ic1 = dde.icbc.IC(geomtime, lambda x: 0.0, lambda _, on_initial: on_initial)
37
38data = dde.data.TimePDE(geomtime, pde, [ic1], num_domain=10000, num_boundary=100, num_initial=500)
39net = dde.nn.FNN([2] + [40] * 3 + [1], "tanh", "Glorot normal")
40model = dde.Model(data, net)
41
42model.compile("adam", lr=1e-3)
43model.train(100000)
44model.compile("L-BFGS", loss_weights=[1.e-1, 1])
45losshistory, train_state = model.train()
46dde.saveplot(losshistory, train_state, issave=True, isplot=True)
Конструисана је мрежа са 3 слоја, са по 40 неурона и активационом функцијом tanh. Генерисана је мрежа података за 10.000 еквидистантних вредности за \(x\) у опсегу \(-20.8 [nm] \, \le x \le 63 \, [nm]\) и са 500 насумичних вредности за \(t\) у опсегу \(0 \, [s] \le t \le 0.4 \, [s]\). Ове генерисане тачке су коришћене као улазни подаци за обуку мреже. У току обуке, од 100.000 епоха, минимизује се резидуал Хакслијеве једначине за мишићну контракцију и резидуал почетног услова, коришћењем Адам оптимизације са стопом учења \(10^{-3}\).
Што се саме имплементације тиче, треба скренути пажњу на неколико битних момената. Као прво, да бисмо формулисали једначине (34) не саветује се коришћење услових израза (if клаузула), већ се иста функционалност интерпретира помоћу TensorFlow израза за знак, ако се он користи као бекенд. На пример:
def g(x):
return 0.5 * (1-tf.sign(x)) * g2 + \
0.25 * (1+tf.sign(x)) * (1-tf.sign(x-h)) * (g1*x/h) + \
0.5 * (1+tf.sign(x-h)) * (fzah*g1*x/h)
У функцији парцијалне диференцијалне једначине имамо нешто другачији проблем. Наиме, морамо да обезбедимо да функција \(n(x,t)\) не почне да узима вредности мање од нуле. Иако сама математичка поставка то дозвољава, подсетимо се да \(n(x,t)\) означава вероватноћу закачињања, па негативна вредност нема никаквог физичког смисла. То ћемо урадити на следећи начин:
def pde(x, n):
dn_dt = dde.grad.jacobian(n, x, i=0, j=1)
loss = dn_dt - (1.0-n) * f(x[:,0:1],a) + n*g(x[:,0:1])
# Obezbedi pozitivna resenja
return loss + n*(1-tf.sign(n))
У последњој линији се вредности функције губитка додаје члан који има ненулту вредност у случају да је \(n\) негативно. На први поглед, било би довољно уместо n*(1-tf.sign(n)) поставити само 1-tf.sign(n). Међутим, испоставља се да тако формирана функција губитка не доводи до конвергенције, јер није диференцијабилна, па оптимизациони алгоритми као што је Adam не конвергирају. Када се пак функција знака помножи са \(n\), добијамо диференцијабилнију функцију губитка, а самим тим и већу вероватноћу конвергенције.
Као и у примеру Пропагација таласа у отвореном каналу, и овде ћемо покушати да додатно смањимо вредност функције губитка методом L-BFGS:
model.compile("L-BFGS", loss_weights=[1.e-1, 1])
losshistory, train_state = model.train()
Веома је важно испоштовати постављене почетне услове, па ћемо им помоћу loss_weights=[1.e-1, 1] дати за ред величине већу тежину од компоненте која следи из саме парцијалне диференцијалне једначине.
Резултати
И овај пример ће услед великог броја колокационих тачака (података) најбоље перформансе имати уколико се извршава на неком графичком процесору који ову масовност уме да паралелизује. На пример, на нашем графичком процесору NVidia Tesla T4 обука траје око 170 секунди, док на осмојезгарном процесору Intel Xeon Silver 4208 на 2.10GHz траје 2150 секунди. То је убрзање од готово 13 пута!
На Сл. 47 се види како је текао процес тренинга НМПФЗ. Уочљиво је да додатно обучавање помоћу L-BFGS дефинитивно има ефекта и да смо помоћу њега спустили вредност губитка за додатни ред величине.
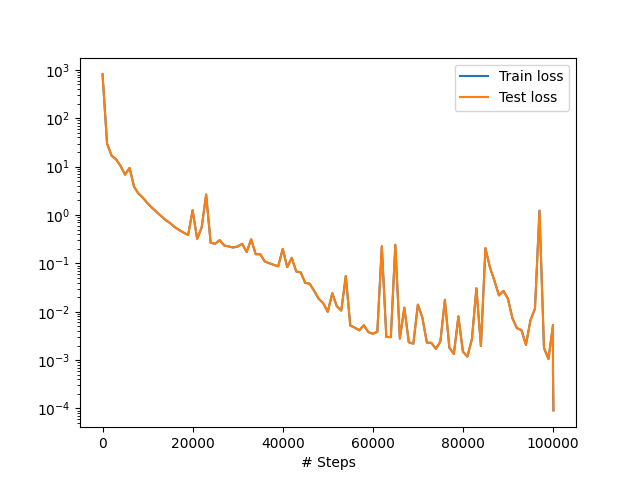
Сл. 47 Функција губитка током обучавања
Тродимензионални приказ резултата дат је на Сл. 48. Из оваквог приказа није погодно утврђивати било какву тачност решења, али је довољан за квалитативни увид. Уочљиво је да близу \(t=0\) (\(x_2\) на слици) има неколико колокационих тачака где је \(n(x,t)<0\), али свеукупно решење делује логично.
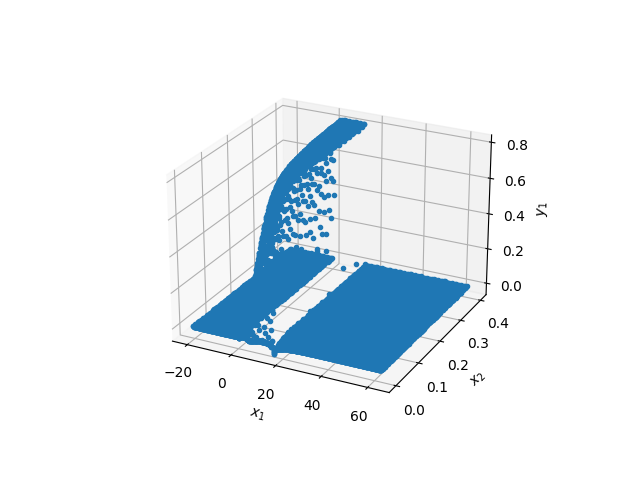
Сл. 48 Тродимензионални приказ добијених резултата. \(x_1\) је просторна координата, а \(x_2\) временска.
Прецизнију визуелну анализу резултата можемо обавити тек графичким представљањем вероватноће закачињања мостова \(n(x,t)\) дуж \(x\) осе у неколико различитих временских тренутака, као што је дато на Сл. 49. Као што смо очекивали, уочљива је мала нестабилност око тачке \(x=h\) у неколико првих временских корака, али се она губи како процес закачињања напредује.
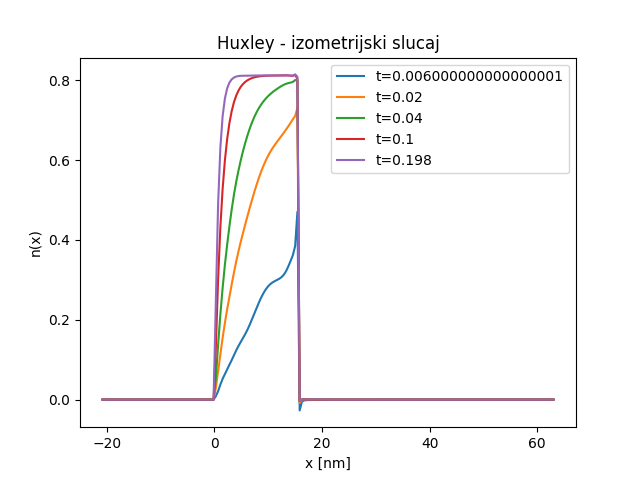
Сл. 49 Величина \(n(x,t)\) у неколико различитих временских тренутака
Упоређивање резултата са онима који су добијени методом карактеристика излази из оквира овог практикума, па ћемо тај део прескочити. На крају је важно напоменути да једну потенцијалну примену НМПФЗ на коју до сада нисмо обраћали пажњу, а може бити од велике користи. Наиме, док код класичних нумеричких метода за решавање парцијалних диференцијалних једначина, решење у временском кораку \(m+1\) зависи од решења које смо имали у временском кораку \(m\). Код свих примера које смо обрадили помоћу НМПФЗ то није случај, јер се време узима као било која друга променљива по којој се врши парцијална диференцијација. Ако погледамо Сл. 49 очигледно је да у тренутку \(t=0,006\) имамо грешку. Међутим, та грешка се не пропагира на касније временске тренутке баш из наведеног разлога.
Овај другачији третман времена као улазне променљиве има импликације и на перформансе. Наиме, када се НМПФЗ модел користи у продукцији, и потребно нам је да знамо нпр. \(n(x,t=t_1)\) није потребно да прођемо кроз све временске кораке \(t \le t_1\), већ одмах можемо да избацимо резултат, једним проласком кроз обучену НМПФЗ. Тиме се време значајно штеди и за неколико редова величине. Тиме се отварају неке нове примене, нарочито у области моделовања на више скала, као на пример у Svičević [Svivcevic20]. Таквим скоком у перформансама било би могуће овакве сложене моделе изводити скоро у реалном времену.